



| Zuletzt aktualisiert: 09.04.2023 |
|
|||||||||
|
|
Datenübertragung zwischen AVRDaten von A nach B zu übertragen ist auf elektrischem Wege eigentlich gar nicht so schwer. Handelt es sich dabei nur um die beiden Werte 0 oder 1, so ist es sogar sehr einfach, indem man die beiden Werte unterschiedlichen Voltpegeln zuordnet. Will man nur 10 Zeichen dieser Art übertragen, muss man eben 10 Leitungen verlegen, wo jede Leitung mit den jeweiligen Voltpegeln versorgt wird.Will man jedoch 1000 Zeichen dieser Art übertragen, so muss man serialisieren, das heißt, daß man die Zeichen nacheinander überträgt. Erst das erste Zeichen, dann das zweite usw. Im besten Fall kann man so 1000 Zeichen über eine einzige Leitung übertragen, man braucht zwar 1000 Mal so lange, als wenn man 1000 Leitungen verlegt hätte, aber man hat 999 Leitungen gespart. Letztlich läuft alles darauf hinaus, dass man Daten serialisieren muß, um sie von A nach B transportieren zu können. Schaut man sich die Serialisierungsmöglichkeiten an, so fällt auf, dass man grundsätzlich auf zwei bestimmte Art und Weisen die serialisierten Daten auf die andere Seite bekommen kann. In beiden Fällen werden Daten so verpackt, dass mehrere Zeichen in einem zeitlichen Versatz hintereinander über eine geringere Anzahl von Leitungen übertragen werden muß. Nun besteht das Problem, dass man den zeitlichen Versatz, also die Zeit, die man zur Übertragung eines Zeichens benötigt irgendwie so abgrenzen muß, dass der Empfänger weiß, wann das Zeichen zuende ist und wann das nächste anfängt.
Zur Datenübertragung zwischen zwei AVRs habe ich mich dafür entschieden, keinen gemeinsamen bekannten Takt zu benutzen, sondern grundsätzlich eine synchronisierte Übertragung zu benutzen. Hier besteht der Vorteil, dass keine genauen externen Quarze nötig sind, sondern dass ggf. die beiden Parteien völlig unterschiedliche Prozessorgeschwindigkeiten haben, vom langsameren Prozessor wird nicht erwartet, dass er seine komplette Rechenpower zur Kommunikation aufwendet. In einem Beispielaufbau mit dem RS232 USB Adapter ist es möglich, von einem mit 16 MHz getakteten AVR (RC-Oszillator) auf einen 16 MHz AVR (Quarz) und von hier aus per USB-Adapter (38400 Baud) etwa 7400 Bytes pro Sekunde fehlerfrei an den PC zu senden, gleichzeitig 7400 Bytes pro Sekunde von AVR 1 zu AVR 2 und ebenfalls 7400 Bytes pro Sekunde von AVR 2 nach AVR 1. Während einer Sekunde wandern also ca. 22kB über die Leitungen. Hiermit wird Debugging von AVRs sehr angenehm. 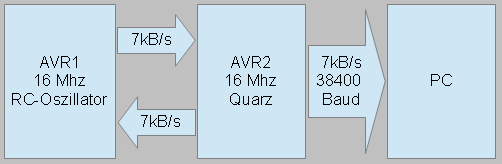
Grundsätzlich baut sich eine solche synchrone Kommunikation so auf, dass der schnellere Prozessor auf die Signale des langsameren Prozessors wartet. Dies kann man auf 3 verschiedene Weisen tun:
Master-/SlavestrukturLeider läßt sich eine solche Kommunikation nicht so aufbauen, dass beide Seiten denselben Code ausführen. Hier bedarf es einer Unterscheidung zwischen Master und Slave. Wer nun welche Rolle bekommt ist eigentlich unerheblich, wichtig ist nur, dass ein Kommunikationsteilnehmer Slave und einer Master ist. Ebenso darf ein AVR auch Master und Slave zugleich sein, allerdings natürlich für zwei verschiedene Kanäle.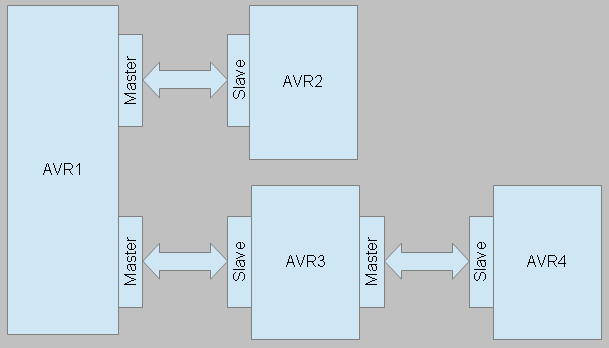
In Kombination mit der Funktionsblock-Lösung ist es möglich, dass ein AVR die Daten mehrerer anderer AVRs einsammelt, und es zu keinen Blockierungen kommt, wenn einer der Kanäle zu einem AVR ausfällt. Headerfiles und IO-PortsSehr häufig findet man in Source-Codes von C-Programmen für AVRs leider folgendes Konstrukt:#define LED1_DDR DDRB #define LED1_PORT PORTB #define LED1_PIN PB0 LED1_DDR |= (1<<LED1_PIN); LED1_PORT |= (1<<LED1_PIN);Schöner, und vor allem lesbarer wird es, wenn man dafür Makros definiert und der Code folgende Gestalt bekommt: #define LED1_DDR DDRB #define LED1_PORT PORTB #define LED1_PIN PB0 configureAsOutput(LED1_DDR, LED1_PIN); switchHigh(LED1_PORT, LED1_PIN);Allerdings bringt uns das bei dem Vorhaben, die Codeteile für die Kommunikation in eine Header-Datei zu gießen, nicht weiter. Der Grund dafür ist, dass man, wenn man einem AVR zwei Master-Schnittstellen verpassen will, bei der Definition der IO-Ports auf die Nase fällt, da man für Schnittstelle 1 Portmakros definieren müßte, aber auch für Schnittstelle 2. Man müßte den Code zweifach vorhalten oder die Verwendung so eingrenzen, dass ein AVR nur eine Slave- und eine Masterschnittstelle haben darf. Bei statischen Lösungen sind oben gezeigte Konstrukte natürlich legitim, allerdings ist es in diesem Falle nicht brauchbar und zu eingeschränkt. Deshalb wird auf variable Portzuordnung mittels Zeigern zurückgegriffen.
volatile unsigned char * LED1_DDR;
volatile unsigned char * LED1_PORT;
volatile unsigned char LED1_PIN;
LED1_DDR = &DDRB;
LED1_PORT = &PORTB;
LED1_PIN = PB0;
configureAsOutput(*LED1_DDR, LED1_PIN);
switchHigh(*LED1_PORT, LED1_PIN);
Hiermit wird es möglich, dass man in einem Programm eines beteiligten AVRs beipsielsweise folgendes schreibt:
#include "transmit.h" // Header für Kommunikation
// Struktur, wo Variablen für die Kommunikation zu anderem AVR aufbewahrt werden
struct Transmitter connect2Avr;
int main() {
// IO-Ports konfigurieren
connect2Avr.in.config.OutputSCL_DDR = &DDRB;
connect2Avr.in.config.OutputSCL_PORT = &PORTB;
connect2Avr.in.config.OutputSCL_PIN = PB4;
connect2Avr.in.config.OutputSDA_DDR = &DDRB;
connect2Avr.in.config.OutputSDA_PORT = &PORTB;
connect2Avr.in.config.OutputSDA_PIN = PB5;
connect2Avr.in.config.InputSCL_DDR = &DDRD;
connect2Avr.in.config.InputSCL_PORT = &PIND;
connect2Avr.in.config.InputSCL_PIN = PIND2;
connect2Avr.in.config.InputSDA_DDR = &DDRD;
connect2Avr.in.config.InputSDA_PORT = &PIND;
connect2Avr.in.config.InputSDA_PIN = PIND3;
// dieser AVR ist Master
FB_TransmitMaster(&connect2Avr); // Erster Aufruf = Ports konfigurieren
unsigned char step = 0;
while(1) {
// Byte senden und empfangen
switch(step) {
case 0:
connect2Avr.in.sendByte = 65; // Byte, das gesendet werden soll
connect2Avr.in.cmdSend = 1; // Senden anstoßen
step = 1;
break;
case 1:
FB_TransmitMaster(&connect2Avr);
if (connect2Avr.out.ready == 1) {
uint8_t result = connect2Avr.out.receiveByte; // empfangenes Byte
// irgendwas mit empfangenen Zeichen tun...
// wieder zum Anfang
step = 0;
}
break;
}
}
return 0;
}
Der Code für die Kommunikation kann auf Anfrage erhalten werden.
|
|||||||||
|
|
||||||||||




